


Le format de la trame IPv4 est le suivant :
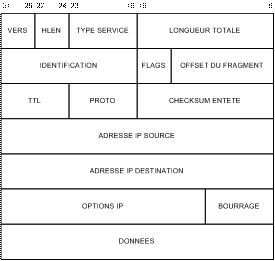
Figure 15 : Le format de la trame IPv4
Le problème le plus connu concerne l'espace d'adressage. Les adresses IP sont actuellement stockées sur 32 bits ce qui permet environ plus de quatre milliards d'adresses, ce qui était suffisant lors de sa mise en place. Ce n’est plus le cas maintenant.
Un autre problème est celui posé par l'explosion de la taille des tables de routage dans l'Internet. Le routage, dans un très grand réseau, doit être hiérarchique avec une profondeur d'autant plus importante que le réseau est grand. Le routage IP n'est hiérarchique qu'à trois niveaux : réseau, sous-réseau et machine.
IPv4 ne permet pas d'indiquer de façon pratique le type de données transportées (TOS ou Type Of Service dans IPv4).
Enfin, IPv4 ne fournit pas de mécanismes de sécurité comme l'authentification des paquets, leur intégrité ou leur confidentialité. Il a toujours été considéré que ces techniques étaient de la responsabilité des applications elles-mêmes.
Le format de la trame IPv6 est le suivant :
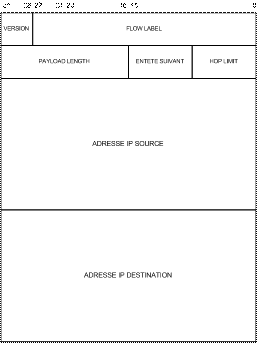
Figure 16 : Le format de la trame IPv6
Bien que plus longue que la version 4 d'IP, l'en-tête d’IPv6 a été simplifiée.
- Version (4 bits): ce champ défini le numéro de version du Protocole IP.
- Flow Label (28 bits): ce champ peut être utilisé par une station pour « marquer » certains paquets afin qu'ils suivent un routage particulier dans un réseau.
- Payload Length (16 bits): longueur des données après l'en-tête IPv6 en octets.
- Entête suivant (8 bits): il identifie le type d'en-tête suivant immédiatement l'en-tête IPv6. Ce champ est le même que le champ protocole d'IPv4.
- Hop limit (8 bits): utilisé pour détruire les paquets qui pourraient rester dans le réseau à la suite de boucles dues aux tables de routage.
- Adresse IP source (128 bits): champ adresse de l'émetteur du datagramme.
- Adresse IP destination (128 bits): champ adresse du destinataire du paquet.
Il existe deux mécanismes de sécurité dans IPv6. Le premier est le mécanisme de l'en-tête d'authentification; le second, une technique d'encapsulation affectée à la sécurité appelée ESP (Encapsulating Security Payload) permettant l'intégrité, l'authentification et la confidentialité.
L'en-tête d'authentification IPv6 cherche à rendre possible l'intégrité et l'authentification des datagrammes IPv6. ESP (ou l'en-tête de confidentialité) pour IPv6 permet d'apporter l'intégrité, l'authentification et la confidentialité dans les datagrammes IPv6.
Il est possible de combiner à la fois ces deux mécanismes d’IPv6 afin d'obtenir un meilleur niveau de sécurité.
Certains aspects propres à la sécurité (comme la protection contre l'analyse du trafic) ne sont pas encore fournis par les mécanismes de sécurité d’IPv6.
Le protocole MPLS (Multiprotocol Label Switching), est un protocole qui utilise un mécanisme de routage qui lui est propre, basé sur l'attribution d'un « label » à chaque paquet. Cela lui permet de router les paquets en optimisant les passages de la couche 2 à la couche 3 du modèle OSI et d'être indépendant du codage de celles-ci suivant les différentes technologies (ATM, Frame Relay, Ethernet etc...)
Le but est d'associer la puissance de la commutation de la couche 2 avec la flexibilité du routage de la couche 3. Schématiquement, on peut le représenter comme étant situé entre la couche 2 (liaison) et la couche 3 (réseau).
L'objectif initial de MPLS était d'apporter la vitesse de commutation de la couche 2 à la couche 3. L'utilisation de « label » permet de prendre des décisions de routage seulement basées sur la valeur du « label » et de ne pas effectuer des calculs complexes de routage portant sur l'adresse IP au niveau de la couche 3 du réseau. Cet aspect performance du protocole est aujourd'hui moins important du fait de l'apparition de composants hardware tels les commutateurs « switchs » de niveau 3.
MPLS apporte cependant plusieurs autres bénéfices pour les réseaux IP :
- Gestion du trafic (Traffic Engineering) c’est à dire la capacité de configurer le chemin que vont emprunter les différents flux sur le réseau et d'associer des caractéristiques de performances à une classe de trafic ;
- Etablissement de VPNs c’est à dire la possibilité d'établir des VPNs sur un réseau MPLS sans la nécessité d'utiliser des protocoles de chiffrement ou des applications clientes particulières ;
- Transport de services associés au niveau 2 ( tels Ethernet, Frame Relay and ATM ) au dessus d'un noyau IP/MPLS ;
- Suppressions des « Multiple layers » : la plupart des fournisseurs de réseau utilisent un modèle de recouvrement où SONET/SDH est déployé en couche 1, le protocole ATM est utilisé en couche 2 tandis que le protocole IP est utilisé en couche 3. En utilisant MPLS, les fournisseurs de réseaux peuvent faire passer plusieurs des fonctions de contrôle de SONET/SDH et d'ATM à la couche 3, simplifiant de ce fait la gestion du réseau et sa complexité.
Un chemin basé sur les mécanismes MPLS (LSP) peut être établi en traversant plusieurs couches de transports de niveau 2 tels que ATM, Frame Relay ou l'Ethernet. Un des gros points forts du protocole MPLS est la capacité de créer les circuits de bout en bout, avec des caractéristiques de performances spécifiques, à travers n'importe quel type de support de transport, éliminant le besoin de réseaux de recouvrement ou de mécanismes de contrôle de niveau 2 seulement.
Dans un réseau mettant en oeuvre le protocole MPLS, tout paquet entrant se voit attribuer un « label » par un Label Edge Router (LER). Les paquets sont routés le long d'un Label Switch Path (LSP) où chaque Label Switch Router (LSR) prend les décisions de routage en s'appuyant seulement sur la valeur des « label ». A chaque « saut », le LSR remplace l'ancien « label » par un nouveau qui indique comment router le paquet au prochain saut.
La séparation des flux entre clients sur des routeurs mutualisés supportant MPLS est assurée par le fait que seul la découverte du réseau se fait au niveau de la couche 3 et qu'ensuite le routage des paquets est effectué en s'appuyant uniquement sur le mécanisme des labels (intermédiaire entre la couche 2 et la couche 3).
Le niveau de sécurité est le même que celui de Frame Relay avec les DLCI au niveau 2.
Le déni de service est en général effectué au niveau 3 (IP). Ici, les paquets seront quand même routés jusqu'au destinataire au travers du réseau MPLS en s'appuyant sur les LSPs.
Les VPNs s'appuyant sur le protocole MPLS, sont différents de l'image classique du VPN, à savoir un tunnel chiffré établi au niveau de la couche 3. Par défaut les tunnels VPN bâtis sur MLPS ne sont pas cryptés et s’apparentent plutôt à des PVCs (Private Virtual Circuit) comme avec ATM ou Frame Relay plutôt qu'à des PVCs établis avec IpSec ou PPTP. Ils s'appuient sur la séparation des paquets sur la valeur de leurs labels et n'utilisent pas de méthode de chiffrement ou d'encapsulation. La valeur de ce label n'est lue que par les LSRs qui appartiennent à un LSP précis.
Les VPN MPLS permettent d'isoler le trafic entres sites n'appartenant pas au même VPN, et en étant totalement transparent pour ces sites entre eux. Ils permettent d'utiliser un adressage privé sans utilisation de fonctionnalité de NAT et d'avoir un recouvrement d'adresses entre différents VPNs.
Trois types de VPN sont bâtis autour du protocole MPLS :
- les VPN de couche 2 ;
- les VPN de couche 3 ;
- les VPN basés sur des routeurs virtuels MPLS.
6.4.2.B.3.b.1° - Les VPN de couche 2 :
Les VPN de niveau 2 ou encore « Transparent LAN Services » (TLS) ou « Virtual Private LAN Services » (VPLS) s’appuient sur un découplage des technologies du cœur du réseau de celles des accès.
Ils s'établissent directement au niveau 2 dans le cas de réseau ATM ou Frame Relay. Ils fournissent des solutions simples pour des connexions point à point via des tunnels permettant le transport de n'importe quel protocole de la couche 3. Les LERs en entrée n'ont pas à gérer les tables de routages et sont donc moins chargés que dans le cas des VPN MPLS de niveau 3.
Ils s'adressent plutôt aux fournisseurs d'accès qui ont peu de VPN à établir et qui veulent une indépendance au niveau du coeur du réseau. Deux solutions concurrentes s’affrontent basées respectivement sur une implémentation du protocole LDP ou du protocole BGP.
6.4.2.B.3.b.2° - Les VPN de couche 3 :
Les VPN MPLS de niveau 3 font l'office d'une RFC 2547. Ils fournissent typiquement plusieurs classes de services via DiffServ utilisé principalement pour éviter la congestion du réseau dans le cas de services temps-réels. Ils peuvent utiliser les mécanismes traditionnels d'accès au réseau tel Frame Relay en s'appuyant sur BGP ou des routes statiques pour router les paquets à travers le réseau du « provider ». Ceci implique qu'ils requièrent une plus grande coordination entre le client et le « provider » que l'approche VPN au niveau de la couche 2. Ils sont actuellement les plus répandus au niveau des offres commerciales.
Une table VRF (VPN Routing and Forwarding) est construite et maintenue au niveau du LER d'entrée. Elle n'est seulement consultable que par les paquets émis par un site faisant parti du VPN (du site émetteur). Cette table contient les routes reçues du site client directement connecté ainsi que des autres LERs. La distribution des routes est contrôlée via EBGP s'appuyant sur des attributs permettant d'identifier l'ensemble des tables VRF auxquelles un LER distribue les routes ainsi que les sites autorisés à lui fournir des routes.
Au sein d'un VPN, un paquet arrivant sur le LER d'entrée MPLS, se voit attribuer suivant la table VRF un premier label représentant le VPN et le routeur LER de sortie de celui-ci au sein du réseau VPN. Pour transiter via le protocole LSP du LER d'entrée jusqu'au LER de sortie, un deuxième niveau de label est empilé permettant la commutation par label classique de proche en proche. Une fois le paquet arrivé au bout du tunnel, le deuxième label est dépilé et le premier label ne donne accès qu'aux informations de routage associé au « bon » VPN.
6.4.2.B.3.b.3° - Les VPN basés sur des routeurs virtuels MPLS :
Une autre façon de mettre en place des VPN est d'utiliser des routeurs virtuels VR (Virtual Router) sur chaque LER du réseau du fournisseur. Sur chaque LER, il peut y avoir une ou plusieurs instances de VR. Un VR supporte un et un seul VPN. Deux LERs communiquent à travers le réseau via un tunnel MPLS ou autre. Un VR est considéré comme une instance de routeur réel et chacun comporte des tables de routage et VRF indépendantes.
Compte tenu de l’explosion du nombre de réseaux et de la difficulté à maintenir de grandes tables de routage IP, des mécanismes de routage dynamiques ont été mis au point. Le premier protocole de routage IP dynamique RIP a été rapidement abandonné car souffrant de nombreuses limitations. L’IETF a proposé le protocole OSPF qui tend à s’étendre dans tous les grands réseaux d’entreprise.
OSPF est un protocole de routage dynamique présentant deux caractéristiques essentielles :
- il s’agit d’un protocole ouvert, son fonctionnement peut être connu de tous ;
- il utilise l’algorithme SPF (Shortest Path First) afin d’élire la meilleure route vers une destination donnée.
A l’intérieur d’une même zone OSPF (regroupement des routeurs OSPF d’un même réseau) les routeurs doivent effectuer les taches suivantes avant de pouvoir effectuer leur travail de routage :
- établissement de la liste des routeurs voisins :
ð chaque routeur OSPF envoie sur chacune de ses interfaces des paquets HELLO permettant de se « presenter » à l’ensemble de ses voisins.
- élection du routeur désigné :
ð dans une zone OSPF, l’un des routeurs doit être élu « routeur désigné » (DR pour « Designated Router ») et un autre « routeur désigné de secours » (BDR pour « Backup Designated Router »). Le routeur désigné sert de référent de la base de données topologique du réseau et permet de répondre aux trois objectifs suivants :
§ réduction du trafic sur l’état des liens du réseau (il n’existe pas d’échange d’informations entre l’ensemble des routeurs du réseau mais uniquement entre les routeurs et le routeur désigné) ;
§ amélioration de l’intégrité de la base de données topologique (car celle-ci est unique) ;
§ accélération du temps de convergence (à l’inverse de RIP) ;
- découverte des routes :
ð chaque routeur établit une relation maître/esclave avec le routeur désigné. Celui-ci initie l’échange d’informations en transmettant au routeur un résumé de sa base de données topologique via des paquets de données LSA (Link State Advertisement). Dans le cas ou le routeur reçoit des informations jusque là inconnues, il demande une information plus complète à l’aide de paquets LSR (Link State Request) auxquels le routeur désigné répond en renvoyant l’intégralité de l’information contenue dans sa base topologique à l’aide de paquets LSU (Link State Update).
- élection des routes à utiliser :
ð une fois en possession de l’intégralité de la base de données topologique, chaque routeur créé sa table de routage en calculant les routes les moins couteuses.
- maintien de la base de données topologique du réseau :
ð lors de la détection d’un changement d’état de liens (des paquets HELLO sont envoyés périodiquement par les routeurs à leurs voisins) par un routeur, celui-ci envoie un paquet LSU sur l’adresse multicast 224.0.0.6 : le routeur désigné ainsi que le routeur de secours désigné se considèrent comme destinataires et diffusent l’information sur l’adresse 224.0.0.5 (tous les routeurs OSPF sans distinction). On parle de protocole d’inondation.
L’inconvénient principal du routage dynamique est la possibilité pour un pirate de fausser les tables de routage par l’insertion de données erronées permettant de dévier tout ou partie des flux de données. Des mécanismes de sécurité ont donc été implémentés au sein d’OSPF permettant de marquer chaque trame OSPF à l’aide d’une prise d’empreinte MD5 incluant une clé pré partagée connue des seuls routeurs de la zone.
Le protocole SNMP (Simple Network Management Protocol) est un protocol utilisé pour surveiller et gérer les ordinateurs sur un réseau. Plusieurs failles de sécurité liées à ce protocole ont été découverts et annoncées par des organismes de sécurité. Un certain nombre d’outils utilisent ces failles sous la forme d'attaques par déni de service, en vue de causer un redémarrage de l'équipement ou même de gagner l'accès privilégié.
Pour parer aux défaillances du protocole SNMP, le protocole SECURE SNMP (S-SNMP) a été proposé en Juillet 1992 par l’IETF via les RFC 1351, 1352, 1353, 1321 en tant que standards proposés. Ce protocole n’est toujours pas implémenté et l’ensemble des grands acteurs du marché recommande de stopper le protocole SNMP !!! Cela ne permet certes pas de régler le problème de la supervision du parc des ordinateurs clients d’une société comme ACME Inc !!!
L’adoption du protocole IP par la quasi-totalité des systèmes informatiques existants rend caduque l’étude des autres protocoles réseaux.